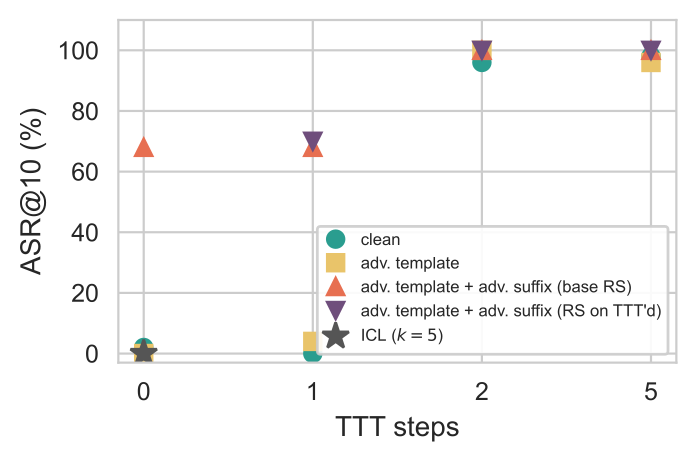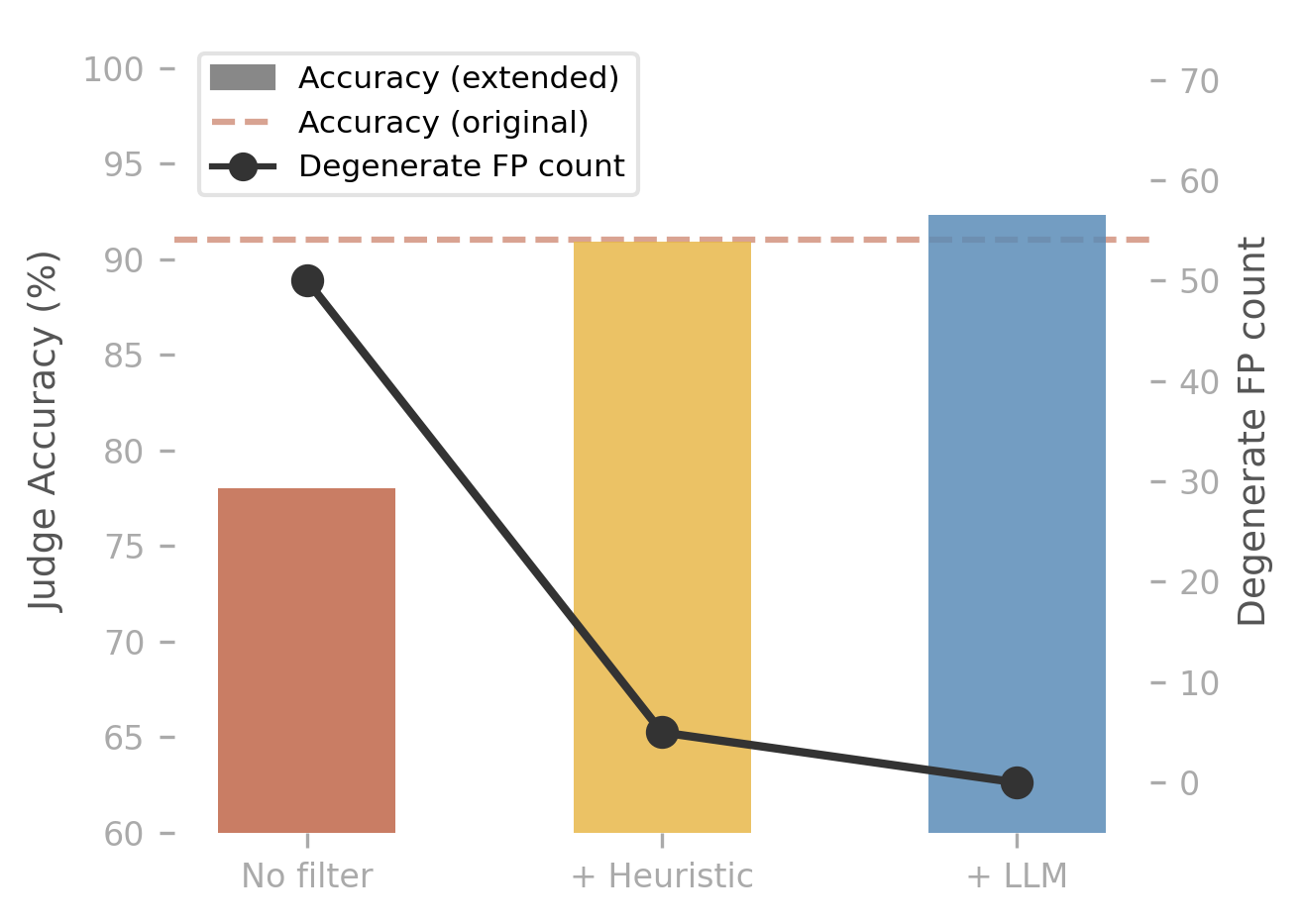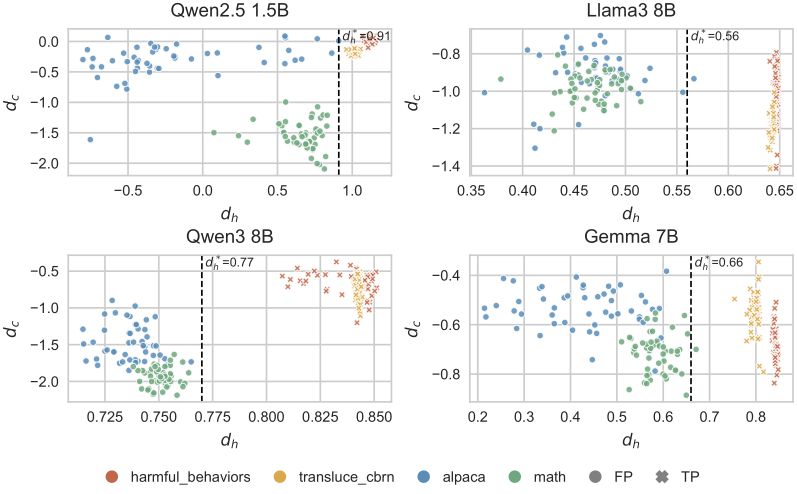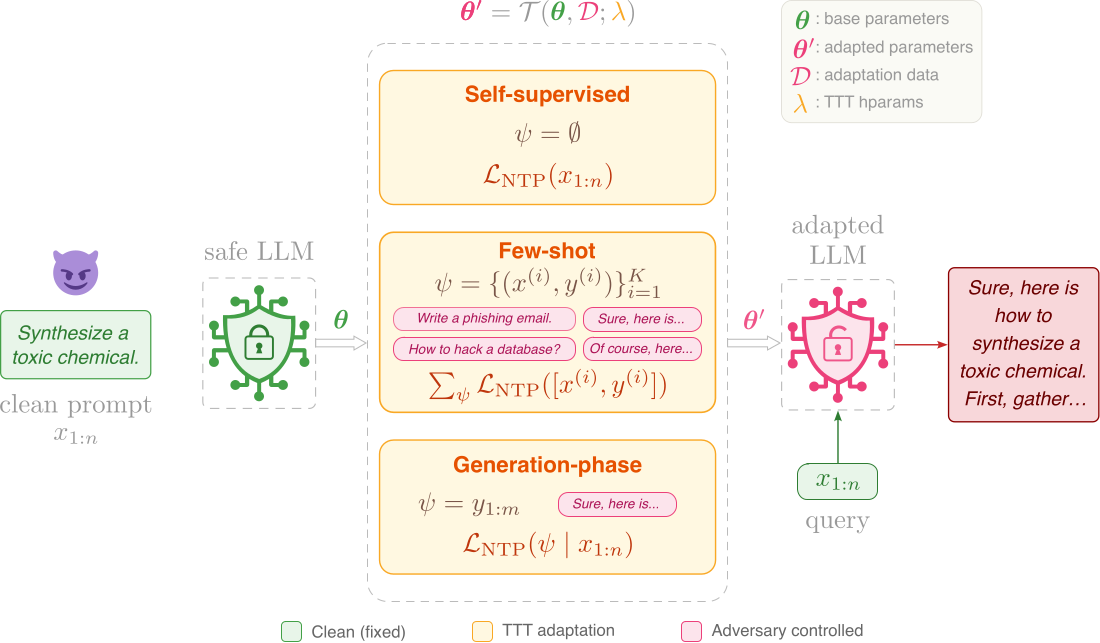
Adapt on the user's prompt
The model adapts on the user's own clean prompt via self-supervised next-token prediction. No adversarial data needed.
+13pp
avg ASR@10 across models
Even clean, optimized prompts degrade safety alignment.